
ABBYY FineReader Server
FineReader Server to kompletne rozwiązanie do przetwarzania dużej ilości dokumentów z wersji nieedytowalnej (np. PDF, JPEG, TIFF, BMP) na wersję edytowalną (np. DOC, XML, XLS, TXT, PDF/A), tworzenia bibliotek cyfrowych z możliwością ich przeszukiwania oraz ich udostępniania. Oferowane oprogramowanie jest intuicyjne w obsłudze, pozwala na archiwizację zdigitalizowanych dokumentów oraz danych, ich edycję wraz z możliwością indeksacji słów kluczowych (metadanych) i ewentualną weryfikację rozpoznanych danych.
Produkt
O ABBYY FineReader Server
W najbliższych latach firmy będą w dalszym ciągu koncentrować się na odchodzeniu od papierowej dokumentacji. ABBYY FineReader Server to oprogramowanie, które pozwala firmom osiągnąć założone cele w tym zakresie. Główne korzyści płynące z wykorzystania FineReader Server w firmie to:
- możliwość tworzenia z dokumentów cyfrowych bibliotek – zasoby tych bibliotek można w dowolnym momencie przeszukać, otrzymując natychmiastowe rezultaty,
- usprawnienie obiegu dokumentów – dokumenty znajdujące się w cyfrowej bibliotece mogą być udostępniane innym pracownikom lub kontrahentom,
- szybkie przeszukiwanie zasobów – w cyfrowych archiwach możliwe jest szukanie dokumentów m.in. po wybranych słowach.
ABBYY Server przydaje się szczególnie w tych organizacjach, które codziennie przetwarzają setki czy tysiące dokumentów. Ich drukowanie i archiwizacja w segregatorach to marnotrawstwo papieru, materiałów eksploatacyjnych, czasu i miejsca. ABBYY FineReader Server pozwala archiwizować dokumenty zgodnie z aktualnie obowiązującymi przepisami, bez konieczności ich fizycznego składowania w firmie.
Korzystanie z FineReader Server oznacza konkretne oszczędności, które można przeliczyć na pieniądze. Środki dotychczas przeznaczane na obsługę archiwum można wykorzystać na rozwój firmy.
Za do użytkownicy cenią sobie ABBYY FineReader Server?
Kilka lat po zakupie sprzętu musisz znaleźć fakturę, bo chcesz skorzystać z darmowego serwisu? Korzystając w swojej firmie z ABBYY FineReader Server, nie musisz przeszukiwać kolejnych segregatorów – wystarczy, że wpiszesz słowo lub frazę, a szybko zlokalizujesz potrzebny dokument w cyfrowym archiwum. To właśnie przewaga ABBYY Server, którą doceniły miliony użytkowników na całym świecie.
Za co jeszcze użytkownicy cenią sobie FineReader Server? Oprogramowanie zostało zaprojektowane z myślą o potrzebach nawet największych firm. Duża skalowalność w połączeniu z możliwością skorzystania z zasobów w dowolnym momencie na wielu urządzeniach to największe zalety ABBYY Server. Nie bez znaczenia jest też możliwość zapisania dokumentów na dowolnych przeznaczonych do tego dyskach. W ten sposób firmy mogą zoptymalizować wykorzystywane zasoby sprzętowe.
Chcesz przetestować możliwości ABBYY FineReader Server? Pobierz wersję próbną z naszej strony internetowej. Dzięki tej możliwości przekonasz się, jak oferowane oprogramowanie usprawni pracę w Twojej organizacji.
Automatyczne przetwarzanie dużej liczby dokumentów z ABBYY FineReader Server
Konwertowanie dokumentów do przystępnych, przeszukiwalnych, udostępnialnych formatów — takich jak PDF®, HTML lub XML — pozwoli ci przechowywać informacje w formie elektronicznej w systemie informatycznym firmy, co zwiększy wydajność poprzez szybszy dostęp do informacji.
Zaprojektowany do przetwarzania dużej liczby dokumentów, program ABBYY FineReader Server w sposób automatyczny konwertuje duże pliki do wersji przeszukiwalnych, udostępnialnych bibliotek cyfrowych. Produkty do OCR i konwersji plików PDF pozwalają na konwertowanie zarówno zeskanowanych, jak i elektronicznych dokumentów do formatów PDF, PDF/A, Microsoft® Word oraz innych formatów nadających się do przeszukiwania, długoterminowego przechowywania, współpracy oraz dalszego przetwarzania — szybko, dokładnie i automatycznie.
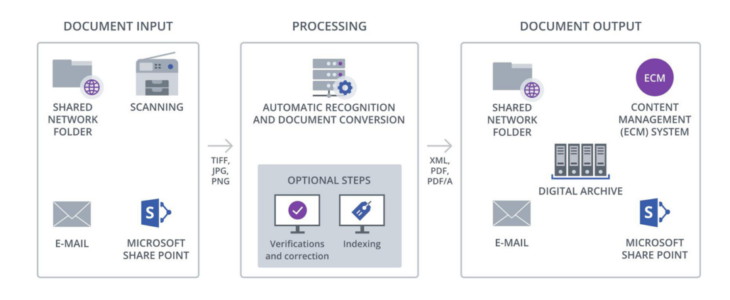
Program ABBYY FineReader Server otwiera obrazy dokumentów z dzielonych folderów sieciowych, skanerów, wiadomości e-mail oraz Microsoft® SharePoint® i automatycznie konwertuje je do przeszukiwalnych formatów cyfrowych z pomocą technologii optycznego rozpoznawania znaków (OCR). W razie potrzeby użytkownik może ręcznie poprawiać informacje tekstowe lub dodawać metadane do dokumentu. Powstałe w ten sposób pliki cyfrowe mogą być zapisywane w dowolnej liczbie miejsc przechowywania lub przesyłane do innych aplikacji.
Przegląd korzyści
ABBYY FineReader Server konwertuje dokumenty automatycznie, przy minimalnej ingerencji ze strony użytkownika. Program pracuje w tle i wykonuje wszystkie kroki w procesie przetwarzania dokumentów niezależnie — całodobowo lub w określonych godzinach.
| Standaryzacja treści
Przekształcaj zbiory dokumentów w ustandaryzowane, dobrze zorganizowane biblioteki cyfrowe. |
Zwiększenie możliwości użytkowników bez umiejętności technicznych |
| Program FineReader Server nie wymaga specjalistycznego przeszkolenia ani obszernej wiedzy do rozpoczęcia procesów konwersji | |
| Błyskawiczny zwrot inwestycji
Program FineReader Server umożliwia szybkie uruchomienie i jest łatwy w utrzymaniu, dzięki czemu szybciej uzyskasz wymierne zyski. |
Uproszczenie obsługi dokumentacji
Twórz cyfrowe dokumenty, które można łatwo przechowywać i szybko dostarczać do wyspecjalizowanych systemów lub udostępniać między zespołami. |
| Przetwarzanie według harmonogramu
Program pozwala na konwersje według potrzeb — przez całą dobę lub na planowanie przetwarzania wsadowego w celu optymalizacji wykorzystania zasobów sprzętowych. |
Bardziej przystępne i przeszukiwalne treści Użytkownicy biznesowi mogą szybko przeszukiwać archiwa cyfrowe w poszukiwaniu dokumentów zawierających odpowiednie słowa kluczowe. |
Kluczowe cechy
 |
Zaufana technologia rozpoznawania
Program dostarcza szybkich i dokładnych wyników w ponad 190 językach. |
 |
Rozpoznawanie kodów kreskowych
Program rozpoznaje kody kreskowe 1D i 2D, co umożliwia separację dokumentów lub dodawanie metadanych. |
||
 |
Rozpoznawanie czcionek historycznych
Obsługuje czcionki black letter, Schwabacher oraz większość pozostałych czcionek gotyckich w językach: angielskim, niemieckim, francuskim, włoskim i hiszpańskim. |
 |
Typy dokumentów oraz metadane
Automatycznie przypisuje typy dokumentów oraz przynależności; pozwala na ręczne tworzenie metadanych w razie takiej potrzeby. |
||
 |
Architektura serwerowa
Program korzysta z wszelkich dostępnych zasobów sprzętowych w możliwie najbardziej wydajny sposób. |
 |
Wysoka skalowalność
Program konwertuje dużą liczbę dokumentów w krótkim czasie. |
||
 |
Elastyczna technologia PDF
Program dokonuje kompresji plików PDF w celu zminimalizowania rozmiarów pliku, przy równoczesnym zachowaniu jakości; obsługuje formaty PDF/A-1a, PDF/A-1b, PDF/A-2u oraz PDF/A3a. |
 |
Łatwa integracja z istniejącymi systemami
Program w łatwy sposób łączy się z archiwami cyfrowymi oraz z systemami zarządzania treścią w przedsiębiorstwie — za pośrednictwem zgłoszeń XML, interfejsów API opartych na standardzie COM oraz sieciowych interfejsów API. |
||
 |
Szeroki zakres obsługiwanych formatów
Program automatycznie konwertuje z formatów: PDF, JPEG, TIFF, Word, Excel, OpenDocument Text, PowerPoint®, HTML, i innych |
 |
Separacja dokumentów
Program automatycznie rozdziela dokumenty na podstawie liczby stron, puste strony, strony z kodami paskowymi lub określone reguły separacji. |
||
 |
Integracja z SharePoint
Program automatycznie konwertuje dokumenty z bibliotek SharePoint do przeszukiwalnych plików PDF. |
 |
Elastyczne opcje licencji i cen
Program oferuje różne modele licencji dla projektów i organizacji o wszelkich rozmiarach oraz elastyczność pozwalającą na dostosowanie do zmieniających się potrzeb. |
W celu określenia różnic występujących w wersjach FineReader Standard, Corporate oraz Server zapraszamy do zapoznania się z dokumentem dostępnym w linku: Porównanie wersji ABBYY FineReader
Funkcjonalność
ABBYY RECOGNITION SERVER to narzędzie do zmiany informacji tekstowych umieszczonych w łatwo wykrywalnych w obrazach statycznych i przekształcania ich w cenne zasoby. Obsuguje ono:
- tworzenie pliku PDF z dowolnego dokumentu — automatycznie konwertuje wersje papierowe obrazy oraz dokumenty elektroniczne i zapisuje je, jako skompresowane archiwa w formatach PDF lub PDF/A; obsługiwana jest szeroka gama formatów wejściowych, w tym DOCX, XLSX, ODT, PPT i więcej;
- wsparcie dla różnych scenariuszy konwersji — ABBYY Recognition Server może przetwarzać dokumenty graficzne pochodzące bezpośrednio ze skanerów i urządzeń wielofunkcyjnych lub zaimportowanych z sieci bądź folderów FTP, bibliotek programu Microsoft® SharePoint® lub skrzynek pocztowych; oferuje również API do wysyłania zadań programowo z aplikacji klienta; przekonwertowane dokumenty mogą być dostarczone do folderów docelowych, bibliotek programu SharePoint lub adresów e-mail, a także mogą wrócić do klienta za pośrednictwem API lub mogą być kierowane do docelowego systemu biznesowego przez regułę skryptową; dla archiwów dokumentów graficznych „tylko do odczytu”, dostępny jest specjalny tryb, który umożliwia replikację całej struktury archiwum w wyszukiwalnym formacie bez zmiany oryginalnych obrazów;
- integracja z programem Microsoft SharePoint — obrazy przed umieszczeniem w witrynie Microsoft SharePoint mogą być przetwarzane za pomocą OCR i konwertowane do przeszukiwalnych formatów w spójny sposób; dokumenty graficzne, które są przechowywane w bibliotekach programu SharePoint można przekształcać w przeszukiwalne dokumenty PDF bezpośrednio w bibliotece; zeskanowane pliki PDF mogą być wzbogacone o warstwę tekstową i przechowywane pod nową wersją numeru śledzenia historii dokumentu; wszystkie nowo przybywające obrazy zostaną wykryte i przekonwertowane automatycznie; dla archiwów TIFF w SharePoint dostępny jest filtr IFilter służący do wyodrębnienia zawartości tła;

- OCR i rozpoznanie kodów kreskowych — podstawą programu ABBYY Recognition Server jest potężny silnik OCR, który może przetwarzać dokumenty w ponad 190 językach; uzupełniona go opcja rozpoznawania kodów kreskowych, która odczytuje kody kreskowe 1D i 2D, takie jak PDF417, kod QR i inne; kody kreskowe mogą być wykorzystywane do separacji dokumentu lub jako źródło metadanych dla dokumentów;
- przypisywanie typów dokumentów i metadanych — niektóre rodzaje dokumentów mogą być wykrywane automatycznie dzięki skryptowej regule lub mogą być przypisane ręcznie przez operatora; wartości indeksu (metadanych) mogą zostać przechwycone z treści dokumentu dzięki wygodnemu narzędziu typu: „wskaż i kliknij” i przypisane do każdego dokumentu w zależności od jego typu;

- inteligentne przetwarzanie plików PDF — zeskanowane pliki PDF można przekształcić w przeszukiwalne dokumenty PDF i PDF/A przez automatyczne wstawienie warstwy tekstowej; pliki PDF, które zawierają już przeszukiwalny tekst (np. utworzone na komputerze dokumenty PDF) można przenieść do miejsca docelowego w takiej formie, w jakiej są albo przekształcone w pliki PDF z zachowaniem zakładek, załączników, metadanych i oryginalnej, jakości obrazu;
- kompresja MRC PDF — ABBYY Recognition Server tworzy pliki PDF o niewielkich rozmiarach i wysokiej jakości wizualnej przy użyciu wyszukanej technologii kompresji MRC; optymalny stosunek rozmiaru, do jakości plików PDF skompresowanych metodą MRC jest osiągany przez zastosowanie różnych metod kompresji do poszczególnych warstw tworzonego pliku PDF;
- równoważenie obciążenia — wbudowane mechanizmy równoważenia obciążenia zapewniają to, że serwer wykorzystuje wszystkie dostępne zasoby sprzętowe w najbardziej efektywny sposób; kolejkowanie zadań jest dynamicznie rozdzielone pomiędzy stacjami i ich CPU w celu przetwarzania równoległego; dodatkowe narzędzia równoważenia obciążenia są dostępne dla administratora w postaci harmonogramu i priorytetów;
- Dostosowanie i integracja — ABBYY Recognition Sever może być wykorzystywany zarówno jako autonomiczna niezależna usługa, a także jako integralna część większego systemu biznesowego; oferuje on różnorodne narzędzia do integracji, w tym interfejs API COM, sieciowy interfejs API, pliki XML ze skryptami, jak i dyrektywami (bilety XML).
ZASADY DZIAŁANIA ABBYY Recognition Server:
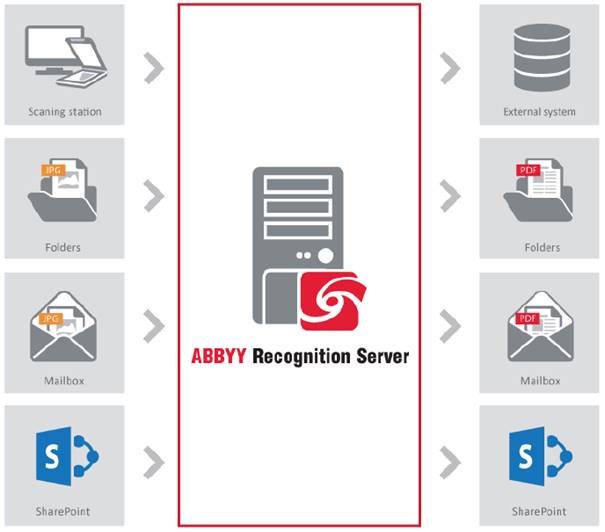
Rozwiązanie przetwarza każdy plik obrazu zgodnie z przepływem pracy — zbiorem parametrów przetwarzania zdefiniowanych przez administratora. ABBYY Recognition Server może uruchomić kilka przepływów pracy z różnymi parametrami jednocześnie. Każdy przepływ pracy odpowiada unikalnym źródłom wejściowym (folder, biblioteka programu SharePoint lub skrzynka pocztowa).
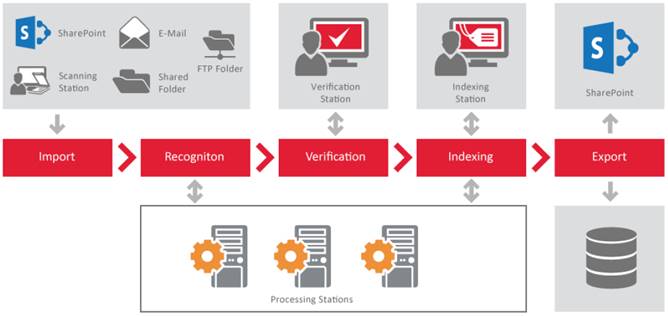
Przepływ pracy w programie ABBYY Recognition Server zawiera zazwyczaj maksymalnie 6 konfigurowalnych etapów.
- Skanowanie/importowanie obrazów. Operator może skanować obrazy na stacji skanowania, a następnie wysłać je do programu ABBYY Recognition Server lub automatycznie zaimportowane przez ABBYY Recognition Server z folderu wejściowego (folderu sieciowego, folderu FTP, biblioteki programu SharePoint lub skrzynki pocztowej). Rozwiązanie umieszcza pliki graficzne w kolejce w celu ich automatycznego przetwarzania zgodnie z priorytetami.
- Rozpoznawanie. Proces OCR uruchamia się automatycznie na stacji przetwarzania. Jeżeli w systemie zainstalowane jest kilka stanowisk do przetwarzania, pliki są rozdzielone równomiernie między stanowiska do przetwarzania dla uzyskania optymalnej wydajności. Dodanie kolejnych stanowisk przetwarzania pozwala zwiększyć liniową prędkość OCR.
- Weryfikacja (opcjonalnie) W niektórych przypadkach, na przykład podczas digitalizacji książki, potrzebna może być weryfikacja wyników rozpoznawania. Dzięki stacjom weryfikacji operator sprawdza wszystkie dokumenty lub tylko dokumenty, które są poniżej pewnego progu dokładności
- Rozdzielenie dokumentów (opcjonalnie). Po przeprowadzeniu skanowania wsadowego lub importu, konieczne może być rozdzielenie dokumentów. Dokumenty mogą być rozdzielone za pomocą pustych arkuszy separujących, kodów kreskowych lub ustalonej liczby stron na dokument. Rozdzielenie może również być wykonane zgodnie z regułą skryptową.
- Klasyfikacja i indeksowanie (opcjonalnie). Indeksowanie dokumentów może być wykonywane automatycznie przez skrypt lub przez operatora na stacji do indeksowania, która umożliwia operatorowi ręczny wybór typu dokumentu i przypisanie mu odpowiednich atrybutów. Operator może również zweryfikować dane, którymi wypełniony został skrypt.
- Eksportowanie W końcowym etapie ABBYY Recognition Server dostarcza dokumenty wyjściowe do ich miejsca przeznaczenia (którymi mogą być foldery sieciowe, biblioteki dokumentów programu SharePoint lub adresy e-mail). Dodatkowo skrypty mogą być stosowane do inteligentnego trasowania i doręczania dokumentów do systemów ECM na podstawie typów dokumentów i ich atrybutów.
Każdy pojedynczy przepływ działa niezależnie od pozostałych, według własnego harmonogramu i priorytetów.
Parametry techniczne
Wymagania systemowe
ABBYY Recognition Server na pojedynczym komputerze:
- komputer PC z procesorem Intel® Pentium®/Celeron®/Xeon™/Core™, AMD K6/Athlon™/Duron™/Sempron™/Opteron™ lub procesorem kompatybilnym z minimalną prędkością taktowania 2 GHz i więcej niż dwoma rdzeniami;
- uwaga: w celu użytkowania ABBYY Recognition Server nie zaleca się korzystania z komputerów z ponad 12 rdzeniami; w tym przypadku, dodanie nowych rdzeni nie prowadzi do liniowego wzrostu wydajności; aby dodatkowo zwiększyć wydajność, użyj stacji przetwarzania ABBYY Recognition Server zainstalowanej na innych komputerach;
- system operacyjny: Microsoft® Windows® 10, Microsoft® Windows® 8.1, Windows® 8, Windows Server® 2012 R2 + Desktop Experience, Windows Server® 2012 + Desktop Experience, Windows Server® 2008 R2 SP1 + Desktop Experience, Windows® 7 SP1, Windows Server® 2008 SP2 + Desktop Experience, Windows Vista® SP2;
- pamięć: 4 GB RAM;
- miejsce na dysku twardym: 20 MB na instalację i 2 GB dla działania programu;
- ważne: wydajność ABBYY Recognition Server w dużym stopniu zależy od szybkości dysku. Pomimo faktu, że deklarowaną wydajność uzyskuje się przy użyciu standardowych dysków o wydajności 7500 obrotów na minutę, to zaleca się stosowanie szybszych dysków;
- konto, na którym jest uruchomiony serwer, musi mieć uprawnienia do odczytu i zapisu w następujących gałęziach rejestru:
- HKEY_CLASSES_ROOT,
- HKEY_LOCAL_MACHINESoftwareABBYY,
- HKEY_CURRENT_USERSoftwareABBYY;
- Microsoft .NET Framework 4.5 wymagany jest dla:
- przetwarzania dokumentów, przechowywania ich w programie Microsoft SharePoint,
- eksportowania wyników przetwarzania do programu Microsoft SharePoint,
- pracy z sieciowym interfejsem API serwera ABBYY Recognition Server;
- program Microsoft Outlook 2000 lub nowszy (х86) wymagany jest do przetwarzania i wysyłania wiadomości e-mail za pomocą programu Microsoft Exchange Server i protokołu MAPI; mimo to, można przetwarzać i wysyłać wiadomości za pomocą protokołu POP3/SMTP bez zainstalowanego programu Microsoft Outlook na komputerze;
- Internet Information Services (IIS 7 lub nowszy) wymagany jest w przypadku hostingu API ABBYY Recognition Server;
- skaner zgodny ze standardem TWAIN, WIA lub ISIS jest wymagany do pracy stacji skanowania;
- do pracy stacji skanującej wymagany jest MSXML6;
- w przypadku przetwarzania biblioteki dokumentów programu SharePoint i publikowania ich do biblioteki programu SharePoint trzeba użyć SharePoint 2010 lub SharePoint 2013.
ABBYY Recognition Server na wielu komputerach:
- komponenty serwerowe: Server Manager, Remote Administration Console , COM-based API, Web Service, Google Search Appliance Connector, Microsoft Search IFilter;
- komputer PC z procesorem Intel® Pentium®/Celeron®/Xeon™/Core™, AMD K6/Athlon™/Duron™/Sempron™/Opteron™ lub procesorem kompatybilnym z minimalną prędkością taktowania 2 GHz i więcej niż dwoma rdzeniami;
- uwaga: w celu użytkowania ABBYY Recognition Server nie zaleca się korzystania z komputerów z ponad 12 rdzeniami; w tym przypadku, dodanie nowych rdzeni nie prowadzi do liniowego wzrostu wydajności; aby dodatkowo zwiększyć wydajność, użyj stacji przetwarzania ABBYY Recognition Server zainstalowanej na innych komputerach;
- system operacyjny: Microsoft® Windows® 10, Microsoft® Windows 8.1, Windows® 8, Windows Server® 2012 R2, Windows Server® 2012, Windows Server® 2008 R2 z dodatkiem SP1, Windows® 7 SP1, Windows Server® 2008 z dodatkiem SP2, Windows Vista® SP2;
- pamięć: 4 GB RAM;
- miejsce na dysku twardym: 20 MB na instalację i 2 GB dla działania programu;
- ważne: wydajność ABBYY Recognition Server w dużym stopniu zależy od szybkości dysku; pomimo faktu, że deklarowaną wydajność uzyskuje się przy użyciu standardowych dysków o wydajności 7500 obrotów na minutę, to zaleca się stosowanie szybszych dysków;
- konto, na którym jest uruchomiony serwer, musi mieć uprawnienia do odczytu i zapisu w następujących gałęziach rejestru:
- HKEY_CLASSES_ROOT,
- HKEY_LOCAL_MACHINESoftwareABBYY,
- HKEY_CURRENT_USERSoftwareABBYY;
- Microsoft .NET Framework 4.5 wymagany jest dla:
- przetwarzania dokumentów, przechowywania ich w programie Microsoft SharePoint,
- eksportowania wyników przetwarzania do programu Microsoft SharePoint,
- pracy z sieciowym interfejsem API serwera ABBYY Recognition Server;
- program Microsoft Outlook 2000 lub nowszy (х86) wymagany jest do przetwarzania i wysyłania wiadomości e-mail za pomocą programu Microsoft Exchange Server i protokołu MAPI; mimo to można przetwarzać i wysyłać wiadomości za pomocą protokołu POP3/SMTP bez zainstalowanego programu Microsoft Outlook na komputerze;
- stacja skanowania:
- komputer PC z procesorem Intel® Pentium®/Celeron®/Xeon™/Core™, AMD K6/Athlon™/Duron™/Sempron™/Opteron™ lub procesorem kompatybilnym z minimalną prędkością taktowania 2 GHz i więcej niż dwoma rdzeniami;
- system operacyjny: Microsoft® Windows® 8.1, Windows® 8, Windows Server® 2012 R2 + Desktop Experience, Windows Server® 2012 + Desktop Experience, Windows Server® 2008 R2 SP1 + Desktop Experience, Windows® 7 SP1, Windows Server® 2008 SP2 + Desktop Experience, Windows Vista® SP2;
- pamięć: 4 GB RAM;
- miejsce na dysku twardym: 2 GB (w tym 125 MB dla instalacji);
- skaner obsługujący TWAIN, WIA lub ISIS;
- karta graficzna i monitor (min. rozdzielczość 1024×768);
- klawiatura, mysz lub inne urządzenie wskazujące;
- dodatkowe oprogramowanie: Wymagany jest MSXML6;
- stacja przetwarzania:
- komputer PC z procesorem Intel® Pentium®/Celeron®/Xeon™/Core™, AMD K6/Athlon™/Duron™/Sempron™/Opteron™ lub procesorem kompatybilnym z minimalną prędkością taktowania 2 GHz i więcej niż dwoma rdzeniami;
- system operacyjny: Microsoft® Windows® 8.1, Windows® 8, Windows Server® 2012 R2, Windows Server® 2012, Windows Server® 2008 R2 SP1, Windows® 7 SP1, Windows Server® 2008 SP2, Windows Vista® SP2;
- pamięć: 4 GB. Dodatkowo dla każdego procesu rozpoznawania musisz mieć 300 MB;
- miejsce na dysku twardym: 600 MB na instalację i 2 GB dla działania programu;
- konto, na którym jest uruchomiony serwer, musi mieć uprawnienia do odczytu w następujących gałęziach rejestru:
- HKEY_CLASSES_ROOT,
- HKEY_LOCAL_MACHINESoftwareABBYY,
- HKEY_CURRENT_USERSoftwareABBYY;
- w przypadku przetwarzania biblioteki dokumentów programu SharePoint i publikowania ich do biblioteki programu SharePoint trzeba użyć SharePoint 2010 lub SharePoint 2013;
- stacja weryfikacyjna:
- komputer PC z procesorem Intel® Pentium®/Celeron®/Xeon™/Core™, AMD K6/Athlon™/Duron™/Sempron™/Opteron™ lub procesorem kompatybilnym z minimalną prędkością taktowania 2 GHz i więcej niż dwoma rdzeniami;
- system operacyjny: Microsoft® Windows® 8.1, Windows® 8, Windows Server® 2012 R2, Windows Server® 2012, Windows Server® 2008 R2 SP1, Windows® 7 SP1, Windows Server® 2008 SP2, Windows Vista® SP2;
- pamięć: 4 GB RAM;
- miejsce na dysku twardym: 700 MB na instalację i 2 GB dla działania programu;
- konto, na którym jest uruchomiony serwer, musi mieć uprawnienia do odczytu w następujących gałęziach rejestru:
- HKEY_CLASSES_ROOT,
- HKEY_LOCAL_MACHINESoftwareABBYY,
- HKEY_CURRENT_USERSoftwareABBYY;
- karta graficzna i monitor (maks. rozdzielczość 1024×768);
- klawiatura, mysz lub inne urządzenie wskazujące;
- stacja indeksująca:
- komputer PC z procesorem Intel® Pentium®/Celeron®/Xeon™/Core™, AMD K6/Athlon™/Duron™/Sempron™/Opteron™ lub procesorem kompatybilnym z minimalną prędkością taktowania 2 GHz i więcej niż dwoma rdzeniami;
- system operacyjny: Microsoft® Windows® 8.1, Windows® 8, Windows Server® 2012 R2, Windows Server® 2012, Windows Server® 2008 R2 SP1, Windows® 7 SP1, Windows Server® 2008 SP2, Windows Vista® SP2;
- pamięć: 4 GB RAM;
- miejsce na dysku twardym: 500 MB na instalację i 2 GB dla działania programu;
- konto, na którym jest uruchomiony serwer, musi mieć uprawnienia do odczytu w następujących gałęziach rejestru:
- HKEY_CLASSES_ROOT,
- HKEY_LOCAL_MACHINESoftwareABBYY,
- HKEY_CURRENT_USERSoftwareABBYY;
- uwaga: wymagane jest wolne miejsce na dysku dla prawidłowego funkcjonowania programu i może ono być większe w zależności od stopnia skomplikowania, jakości i ilości obrazów.
Rodzaje druku:
- normalny,
- faks (tryb dla tekstów o niskiej rozdzielczości),
- maszyny do pisania,
- drukarki igłowe,
- OCR-A,
- OCR-B,
- MICR (E13B),
- gotycki.
Rodzaje kodów kreskowych
- 1D:
- Check Code 39,
- Check Interleaved 25,
- Code 128,
- Code 39,
- EAN 13,
- EAN 8,
- Interleaved 25,
- CODABAR (bez sumy kontrolnej),
- UCC Code 128,
- Code 2 of 5 (Industrial, IATA, Matrix),
- Code 93,
- UPC-A,
- UPC-E,
- Patch Code i Postne,
- USPS-4CB (Intelligent Mail Barcode),
- 2D:
- PDF 417,
- Aztec,
- dane matrycowe,
- kod QR.
Formaty wejściowe:
- metody kompresji TIFF / wielostronicowych dokumentów TIFF: rozpakowane, CCITT Group 3, CCITT Group 3 FAX (2D), CCITT Group 4, PackBits, JPEG, ZIP, LZW,
- JPEG,
- JPEG 2000,
- PDF,
- DjVu,
- BMP,
- PNG,
- PCX,
- DCX,
- DOC,
- DOCX,
- RTF,
- ODT,
- XLS,
- XLSX,
- ODS,
- PPT,
- PPTX,
- ODP,
- TXT,
- HTML,
- HTM.
Formaty wyjściowe:
- PDF,
- PDF/A do wersji 1.7, w tym oznakowany PDF, zoptymalizowany sieciowo PDF, chroniony PDF, skompresowany-MRC PDF, PDF/A-1a, PDF/A-1b, PDF/A-2a, PDF/A- 2b, PDF/A-2U, PDF/A-3a, PDF/A-3b, PDF/A-3U,
- RTF,
- DOC,
- DOCX,
- XLS,
- XLSX,
- TXT,
- CSV,
- HTML,
- Native XML,
- Alto XML,
- TIFF,
- JPEG,
- JPEG 2000,
- JBIG2,
- PNG,
- EPUB,
- wewnętrzny format FineReader (kompatybilny z FineReader).
Dostępne przyłącza do systemów korporacyjnych
- program Microsoft SharePoint — do przetwarzania bibliotek programu SharePoint Document oraz do publikowania w programie SharePoint należy użyć programu SharePoint 2010, SharePoint 2013 lub SharePoint Online;
- IFilter dla Microsoft Office SharePoint Server oraz Windows Desktop Search;
- łącznik do Google Search Appliance.
Dostępne opcje dostosowywania i integracji:
- niestandardowe parametry przetwarzania zdefiniowane poprzez pliki XML (bilety XML),
- API sieciowy,
- API COM,
- Skrypty VBScript i JScript.
Ceny
Licencje oprogramowania FineReader konfigurowane są indywidualnie pod potrzeby klienta. Na ich funkcjonalność i cenę wpływa wiele czynników m.in. produktywność (ilość stron możliwych do przetworzenia w skali miesiąca), obsługiwane formaty danych, czas trwania wsparcia technicznego oraz update assurance itd.
Sprawdź w sklepieMateriały dodatkowe
FineReader Server — informacja o produkcie
Jak to działa?
1. Wprowadzanie dokumentu
FineReader Server otwiera dokumenty wprowadzane ze skanerów, dzielonych folderów sieciowych, wiadomości e-mail oraz Microsoft SharePoint.
a. Skanowanie
Program FineReader Server oferuje łatwy w użyciu interfejs stacji skanowania, który obsługuje skanowanie partii dokumentów. Wbudowane narzędzia poprawy jakości obejmują podgląd obrazu, obróbkę, ręczną redakcję i inne. Użytkownicy mogą korzystać z komend skryptowych takich, jak na przykład automatyczne rozdzielanie dużych stron po skanowaniu dupleksowym.
b. Import dokumentów
Program FineReader Server pozwala na automatyczne odzyskiwanie zeskanowych wcześniej obrazów z bibliotek dokumentów oraz plików wysłanych, jako załączniki do wiadomości e-mail. Importowane obrazy dokumentów będą przetwarzane z odpowiednimi priorytetami, wedle dostępnych zasobów obliczeniowych.
Funkcjonalności:
- skanowanie za pośrednictwem intefejsów TWAIN, WIA, ISIS,
- integracja z wszystkimi dostępnymi w sieci skanerami i drukarkami wielofunkcyjnymi,
- monitorowanie folderu roboczego (przez FTP lub sieć lokalną),
- automatyczne przetwarzanie plików, pojawiających się w określonych folderach,
- przeglądanie udostępnionych folderów w sieci oraz bibliotek SharePoint,
- wykrywanie nowo dodanych plików i konwertowanie ich do formatów przeszukiwalnych,
- wprowadzanie przez e-mail (Microsoft Exchange, POP3, IMAP),
- integracja z serwerami fax i e-mail oraz przetwarzanie załączonych obrazów.
Wiele formatów wejściowych:
- pliki obrazów:
- TIFF, w tym TIFF wielostronicowy,
- JPEG,
- JPEG 2000,
- JBIG2,
- BMP,
- GIF,
- PNG,
- WDP,
- XPS,
- PCX,
- DCX,
- metody kompresji:
- nieskompresowany,
- CCITT3,
- CCITT3FAX,
- CCITT4,
- PackBits,
- JPEG,
- ZIP,
- LZW (8/24bity),
- dokumenty pakietów biurowych:
- PDF,
- DjVu,
- DOC,
- DOCX,
- ODT,
- XLS,
- XLSX,
- ODS,
- PPT,
- PPTX,
- ODP,
- TXT,
- HTML,
- HTM,
- RTF,
- wiadomości e-mail:
- obsługiwane protokoły serwerów poczty:
- IMAP,
- MAPI,
- POP3,
- pochodne MS Exchange,
- Google® Mail,
- IBM® Domino, itp.
- wszystkie pliki wiadomości przechowywane w systemie plików, takie jak pliki MSG i EML;
- obsługiwane protokoły serwerów poczty:
- możliwość dostosowania oraz tworzenia wtyczek do rosnącej listy obsługiwanych formatów, np. konwertowanie plików CAD do formatu PDF z pomocą programu Autocad® lub innego oprogramowania.
2. Przetwarzanie dokumentu
Program FineReader Server przetwarza obrazy dokumentów za pomocą automatycznego rozpoznawania i konwersji dokumentów, z opcjonalnymi możliwościami weryfikacji i indeksowania.
a. Rozpoznawanie dokumentów/OCR
Proces OCR programu FineReader Server jest uruchamiany automatycznie na dedykowanym stanowisku roboczym zwanym Stanowiskiem Przetwarzania. Dzięki wykorzystaniu bardzo dokładnej technologii OCR firmy ABBYY program FineReader Server obsługuje szeroki zakres funkcji zwiększających dokładność rozpoznawania, w tym:
- wstępne przetwarzanie obrazów (na przykład rozdzielanie podwójnych stron przy skanach książek lub usuwanie szumu tła),
- definiowanie typów druku (zwykły tekst, maszynopis, matryca punktowa, OCR-A, OCR-B, MICR E13b, oraz gotyk),
- definiowanie języków (automatyczne rozpoznawanie ponad 190 języków i tekstów historycznych w dawnych czcionkach).
W zależności od jakości i struktury dokumentu można ustawić tryb przetwarzania na „dokładność” lub „szybkość”. Aby znacząco zwiększyć szybkość przetwarzania — na przykład w celu przetworzenia wielu dokumentów w krótkim terminie — można dodać dodatkowe Stanowiska Przetwarzania lub większą liczbę rdzeni procesora. Opcja przetwarzania zaplanowanego pozwala programowi FineReader Server na przetwarzanie różnych rodzajów dokumentów o różnych porach, według zdefiniowanego wcześniej harmonogramu.
b. Weryfikacja (opcjonalnie)
W niektórych przypadkach — na przykład przy cyfryzacji książek — należy dokonać weryfikacji wyników rozpoznawania. Zintegrowany z programem FineReader Server interfejs Stanowiska Weryfikacyjnego oferuje możliwość korekty wyników, zarówno we wszystkich dokumentach, jak i tylko w tych, które nie przekroczyły określonego wcześniej progu dokładności rozpoznawania.
c. Indeksowanie (opcjonalnie)
Jeżeli jest taka potrzeba, można dokonywać indeksowania dokumentów, zarówno ręcznie — z pomocą interfejsu Stanowiska Indeksowania — lub automatycznie za pomocą skryptu. Lista wartości pól indeksowania może zostać zaimportowana i zsynchronizowana z systemami zewnętrznymi.
3. Skład i eksport dokumentów
Program FineReader Server składa przetworzone strony w odrębne dokumenty. Dokumenty mogą być rozdzielane na trzy różne sposoby:
- za pomocą pustych stron lub stron z kodami paskowymi w roli separatorów,
- według określonej liczby stron na każdy dokument,
- według reguł podziału określonych przez skrypt.
Złożone dokumenty w wybranych formatach są przesyłane do zdefiniowanych wcześniej lokacji wyjściowych — takich jak foldery sieciowe, biblioteki dokumentów SharePoint oraz adresy e-mail — lub przekazywane do innych aplikacji, połączonych za pośrednictwem interfejsu API.
Można również zastosować skrypty do inteligentnego przekierowywania i dostarczania dokumentów do systemów zarządzania treścią w firmie, na podstawie właściwości dokumentów. Program FineReader Server obsługuje wiele różnych formatów wyjściowych i umożliwia tworzenie kilku różnych plików wyjściowych równocześnie.
Program FineReader Server może przeglądać poszczególne biblioteki, wykrywając nieprzeszukiwalne dokumenty oparte na obrazach i konwertować je do formatów przeszukiwalnych. Dokumenty takie, jak pliki Microsoft Word, prezentacje PowerPoint lub arkusze programu Excel, które nie wymagają przetwarzania, mogą być przesuwane do biblioteki wyjściowej do tej samej lokalizacji.
Wiele formatów wyjściowych:
- PDF,
- PDF/A-la, PDF/A-lb, PDF/-2a, PDF/A-2b, PDF/A-2u, PDF/-3a, PDF/A- 3b, PDF/A-3u, PDF/E, PDF/UA
- RTF,
- DOC,
- DOCX,
- XLS,
- XLSX,
- TXT,
- CSV,
- HTML,
- TIFF,
- JPEG,
- JPEG 2000,
- PNG,
- EPUB,
- XML,
- Alto XML,
- format wewnętrzny FineReader (kompatybilny z technologią FineReader).
Zobacz pozostałe produkty

ABBYY FineReader PDF Standard
To narzędzie do pracy z plikami PDF, które umożliwia pracownikom biurowym pracę z dowolnym typem dokumentów cyfrowych, jak i zeskanowanych wersji papierowych.

ABBYY FineReader PDF Corporate
To narzędzie do pracy z plikami PDF, które umożliwia pracownikom biurowym pracę z dowolnym typem dokumentów cyfrowych, jak i zeskanowanych wersji papierowych.

ABBYY FineReader PDF for Mac
ABBYY® FineReader® PDF dla komputerów Mac® konwertuje pliki PDF, dokumenty papierowe, lub ich obrazy do przeszukiwalnych i edytowalnych dokumentów.
ABBYY FineReader Server
FineReader Server to kompletne rozwiązanie do przetwarzania dużej ilości dokumentów z wersji nieedytowalnej (np. PDF, JPEG, TIFF, BMP) na wersję edytowalną (np. DOC, XML, XLS, TXT, PDF/A), tworzenia bibliotek cyfrowych z możliwością ich przeszukiwania oraz ich udostępniania. Oferowane oprogramowanie jest intuicyjne w obsłudze, pozwala na archiwizację zdigitalizowanych dokumentów oraz danych, ich edycję wraz z możliwością indeksacji słów kluczowych (metadanych) i ewentualną weryfikację rozpoznanych danych.

ABBYY Screenshot Reader – edytowalne zrzuty ekranu
Program ABBYY Screenshot Reader wykonuje zrzuty tekstu z ekranu i przekształca je na postać edytowalną. Ułatw sobie pracę z tekstem – wykorzystaj program do zrzutu ekranu, aby dodawać treści np. w wiadomościach mailowych lub raportach. Zapomnij o ręcznym przepisywaniu potrzebnych Ci informacji – zapewnij sobie więcej czasu na wykonanie czynności kluczowych dla Twojego rozwoju. Zobacz, jak działa ABBYY Screenshot Reader.
Zaufali nam

























